
Stirling-Tools/Stirling-PDF



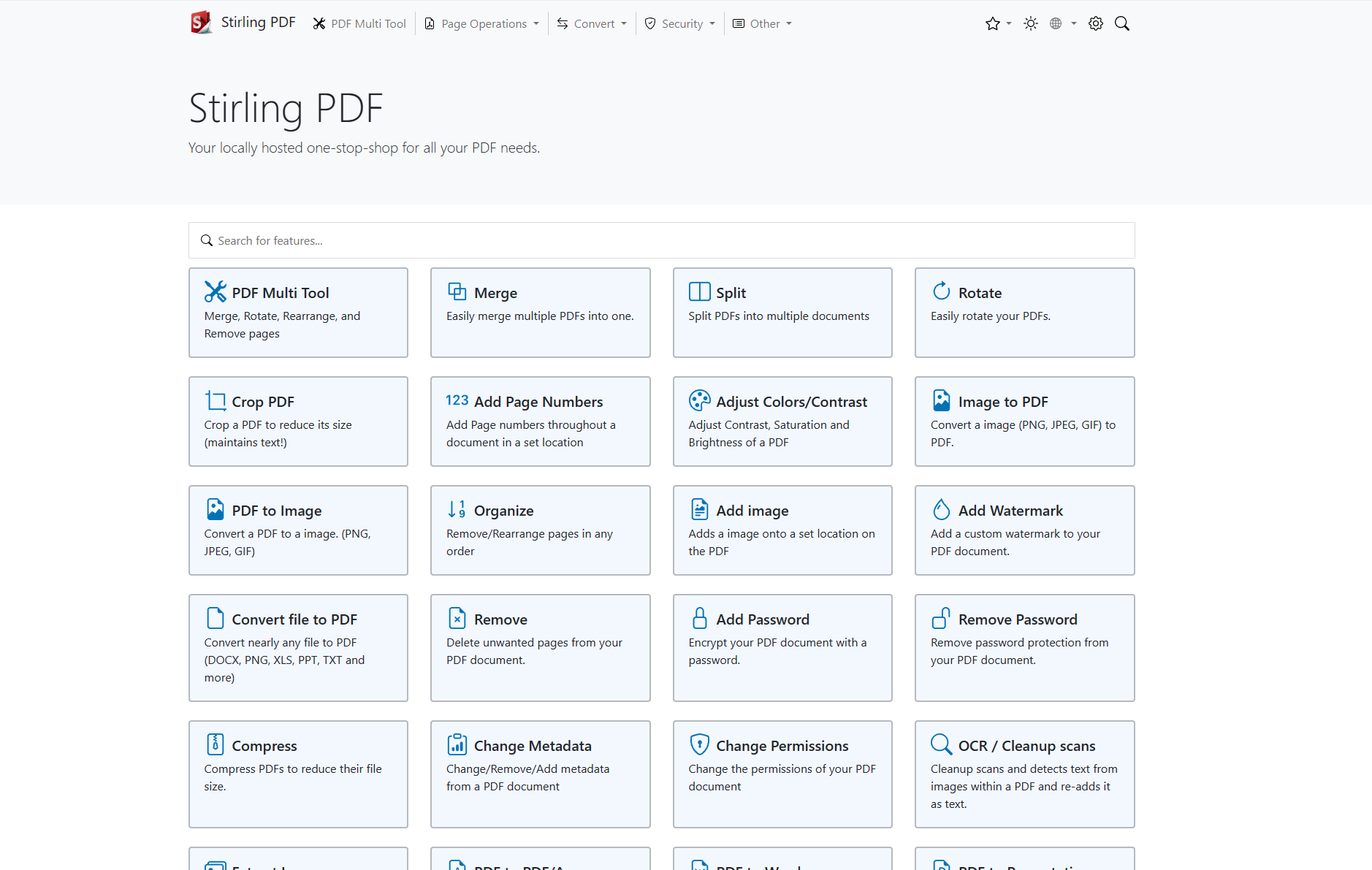
这个项目是 Stirling-PDF,它是一个功能强大的基于本地主机的 Web PDF 操作工具,使用 Docker 进行部署。其主要功能包括分割、合并、转换、重新组织 PDF 文件以及添加图片、旋转和压缩等多种操作。该项目的核心优势和关键特点包括:
- 不会发出任何记录或跟踪请求;
- 所有文件和 PDF 都仅存在于客户端侧,在任务执行期间仅驻留在服务器内存中,或者临时驻留在用于执行任务的文件中;
- 提供暗黑模式支持;
- 支持自定义下载选项,并提供 API 用于与外部脚本集成;
- 可选择登录认证支持。
build-trust/ockam



Ockam 是一套开源编程库和命令行工具,用于协调端到端加密、相互认证、密钥管理等功能。其主要功能包括构建安全的分布式应用程序,并提供终点对终点数据真实性、完整性和保密性的保障。 该项目的关键特点和核心优势包括:
- 提供强大且简单易用的协议
- 基于身份验证与策略驱动,为应用层提供精确授权及认证
- 支持通过多跳传输路由创建安全通道
- 可在企业消息传递系统中引入端到端加密
BartoszJarocki/cv




这是一个简单的网页应用程序,可以呈现出具有适合打印的布局的极简主义简历。它使用 Next.js 和 shadcn/ui 构建,并部署在 Vercel 上。
nodejs/undici



undici 是一个为 Node.js 从头开始编写的 HTTP/1.1 客户端。该项目主要功能包括提供 HTTP 请求和响应处理,以及实现 fetch 标准。其核心优势和关键特点包括:
- 提供高性能:在基于 Unix 套接字连接上进行了简单的 基准测试后,undici 相比其他方法有着更快的请求速度。
- 支持多种 API 方法:支持常用 API 方法如 request、stream、pipeline 等,并且可以设置全局调度器来使用这些通用 API 方法。
- 遵循规范:虽然不完全遵守 Fetch Standard 或者 HTTP/1.1 specification 中所有内容,但对大部分内容都做到了兼容与支持。
HolographicWings/TOTK-Mods-collection



这个项目是一个为《塞尔达传说:王国之泪》(TOTK) 提供的 Mod 集合。该项目主要功能包括动态帧率匹配、分辨率调整和图形优化等。以下是该项目的核心优势和关键特点:
- 动态 FPS:根据您的帧率与游戏时钟进行匹配,修复慢动作/加速现象。
- 分辨率配置文件:针对不同版本提供了多种分辨率选项。
- 图像质量改进:增强模型细节,并且可以通过减少模型切换来提高性能。
- 禁用内部 FSR 降频、禁用 FXAA 效果以及其他图形相关修改。
此外还有一些额外好处,如控制器界面修改、无限耐久度等 Cheat 代码可供选择使用。总体而言,这个开源项目为《塞尔达传说:王国之泪》游戏添加了许多实用的功能和改进选项。
georgia-tech-db/evadb



EvaDB 是一个用于 AI 应用的数据库系统,它可以让软件开发人员只需几行代码就能构建 AI 应用。其强大的 SQL API 简化了结构化和非结构化数据的 AI 应用开发过程。EvaDB 具有以下核心优势:
- 可以轻松连接到诸如 PostgreSQL 或 S3 存储桶等数据源,并使用 SQL 查询来构建基于 AI 的应用。
- 支持多种类型 (包括结构化、非结构化和应用程序) 的数据源,例如 PostgreSQL、SQLite、MySQL、MariaDB 等。
- 提供预训练好的模型库 (如 Hugging Face,Open AI,YOLO),支持各种任务,包括文本分类、图像分割和对象检测等。
- 可以创建或微调回归、分类和时间序列预测模型,并支持 Ludwig,Sklearn,Xgboost 等 AutoML 框架。
- 通过缓存机制、批处理和并行处理实现更快速度高效率地进行 AI 查询操作。