
google/flatbuffers



flatbuffers 是一个跨平台的序列化库,旨在实现最大内存效率。它允许您直接访问序列化数据而无需先进行解析/拆包,同时具有很好的向前/向后兼性。 以下是 flatbuffers 项目的主要功能、关键特性核心优势:
- 内存效率:flatbuffers 通过直接访问序列化数据而不需要解析,实了最大内存效率。
- 跨语言支持:提供种流行编程语言的代码生成和运行时库。
- 平台支持:支 Windows、macOS、Linux 和 Android 等多个平台。
- 版本控制:使用日期格式作为版本号,并确保数据可在不同语言和模式版本间取。
argilla-io/argilla



argilla 是一个协作平台,为需要高质量输出、完全数据所有权和整体效率的 AI 工程师和领域专家提供支持。 主要功能、关键特性、核心优势:
- 帮助用户通过数据质量来提高 AI 输出质量。
- 提供工具让用户掌控自己的数据和模型。
- 通过与数据更互动的方式快速迭代正确的数据和模型,从而提高效率。
- 可以用于创建开源数据库或者模型,并且有很多案例可以参考。
vladmandic/automatic



automatic 是一个实现了稳定扩散和其他基于扩散的生成图像模型的高级实现。
- 支持多个后端,包括 Diffusers 和 Original
- 支持多种 UI,包括 Standard 和 Modern
- 支持多种扩散模型,如 Stable Diffusion、SD-XL、LCM 等等
- 内置控制文本、图像、批处理和视频处理功能
- 多平台支持,包括 Windows、Linux 和 MacOS 等等,并且具有自动检测和调整功能
- 优化处理性能,并支持最新的 torch 发展以及多个编译后端:Triton, ZLUDA, StableFast 等等
rashadphz/farfalle



farfalle 是一个开源的 AI 搜索引擎,可以在本地或云端运行语言模型。 farfalle 解决的核心问题是提供自托管的本地或云端语言模型搜索引擎。
- 可以在本地或云端运行 LLM (llama3, gemma, mistral) 语言模型。
- 提供了基于 llama3 的问题回答演示。
- 使用 Next.js 和 FastAPI 构建前后端。
- 使用 Tavily 进行搜索 API。
- 支持 Docker 部署和环境变量配置。
phidatahq/phidata



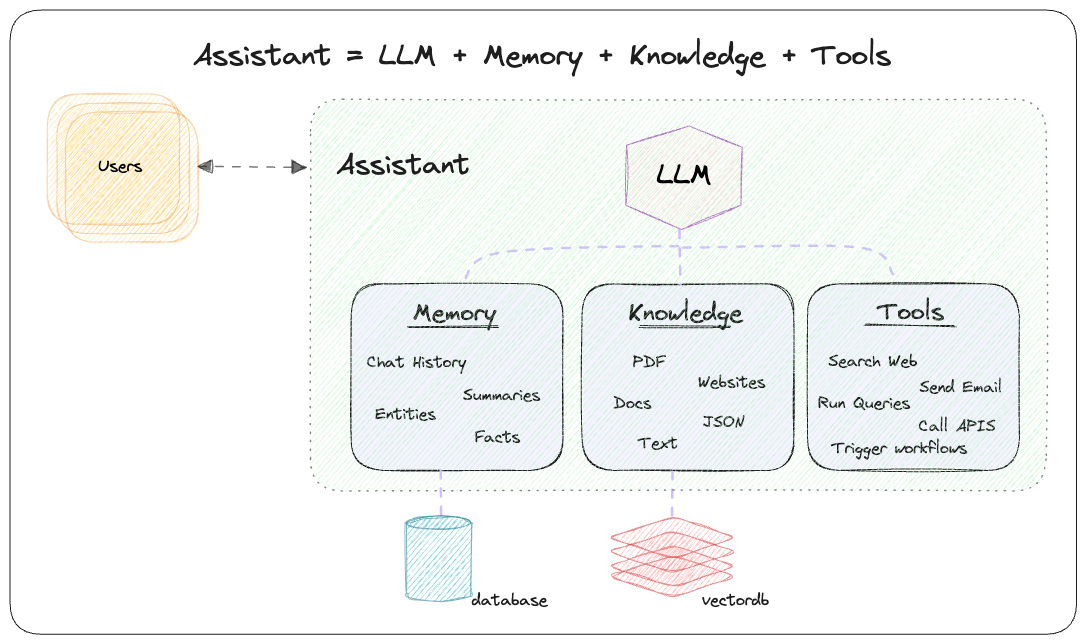
phidata 是一个使用函数调用构建 AI 助手的工具包。
- 创建助手
- 添加工具(函数)、知识(vectordb)和存储(数据库)
- 使用 Streamlit、FastApi 或 Django 提供服务来构建您的 AI 应用程序
- 提供快速启动指南和示例演示应用程序展示了函数调用的优势
- 可以通过预先构建模板轻松部署到 AWS 上