ali-vilab/VGen



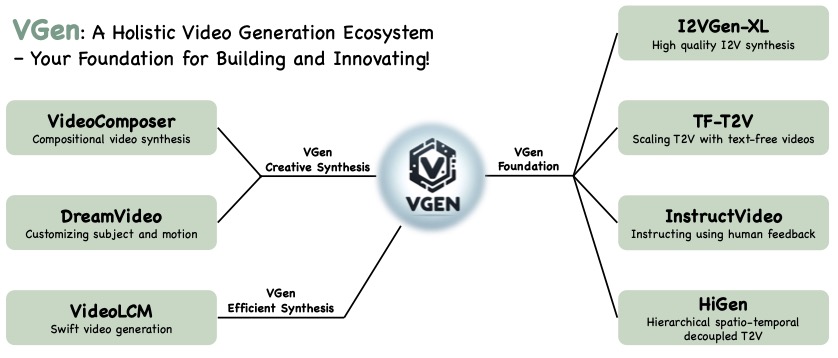
VGen 是一个基于扩散模型的全面视频生成生态系统。 VGen 可以从输入的文本、图像、期望运动、期望主题甚至反馈信号中生成高质量的视频。它还提供了各种常用的视频生成工具,如可视化、采样、训练和推理等。该项目包括以下方法的实现:
- I2VGen-xl:通过级联扩散模型进行高质量图像到视频合成
- VideoComposer:具有运动可控性的组合式视频合成
- 文本到视频生成的分层时空解耦
- 利用无文本视频扩大文本到视频生成规模的秘诀
- InstructVideo:使用人类反馈指导视频扩散模型
- DreamVideo:使用定制主题和动作创作您梦想中的影片 核心优势:
- 支持多种类型数据输入,包括文本、图像等。
- 提供丰富而易用的工具集,方便用户进行可视化分析、训练和推理。
- 实现了多个先进且高效率算法,并不断更新迭代以提升性能。
- 开源并积极与社区互动,在开发过程中接受用户反馈并发布新版本。
arcee-ai/mergekit



mergekit 是一个用于合并预训练语言模型的工具包,支持多种合并方法,包括 TIES、线性和 slerp。该工具包还可以实现对语言模型进行分段组装。 其主要功能和核心优势如下:
- 支持多种合并方法:TIES、线性和 slerp
- 可以定义不同层次的参数,并且能够根据条件设置张量名称过滤器来指定参数
- 提供了灵活的配置文件格式,允许用户自定义各项操作及相关参数
- 通过 字段确定使用哪个标记生成器 (tokenizer),从而影响嵌入 (embeddings) 和语言模型头部 (lm heads) 的合并方式
open-mmlab/Amphion



Amphion 是一个用于音频、音乐和语音生成的工具包。 该项目旨在支持可复制的研究,并帮助初级研究人员和工程师开始进行音频、音乐和语音生成研究与开发。 Amphion 的主要功能和核心优势包括:
- TTS:文本转语音
- SVC:歌声转换
- TTA:文本到声学
- Vocoders 支持多种广泛使用的神经声码器,如 GAN-based vocoders, Flow-based vocoders, Diffusion-based vocoders 和 Auto-regressive based。
- Amphion 实现了几种最先进的模型架构,包括扩散式、变压器式、VAE 和流式模型。
meta-llama/llama-recipes



是用于与 Meta Llama3 模型进行微调的脚本集合,支持可组合的 FSDP 和 PEFT 方法,适用于单节点和多节点 GPU。它支持默认和自定义数据集,用于应用如摘要生成和问答系统。此项目还提供多种候选推理解决方案,如 HF TGI 和 VLLM,可在本地或云端部署。演示应用展示了如何在 WhatsApp 和 Messenger 上展示 Meta Llama3 的能力。
- 支持 Meta Llama3 模型的微调和定制化
- 使用 FSDP 和 PEFT 方法进行分布式训练
- 支持摘要生成和问答系统等应用
- 可用于本地和云端部署
- 演示应用展示了在 WhatsApp 和 Messenger 上的应用场景
sweepai/sweep




sweep 是一个开源的基于人工智能的软件开发者,专注于解决小功能和错误修复。 该项目主要功能、关键特性、核心优势包括:
- 将 issues 直接转换为拉取请求(无需集成开发环境)
- 处理开发者对其拉取请求的回复和评论
- 使用依赖图、文本和向量搜索来理解代码库
- 运行单元测试和自动格式化以验证生成的代码
- 通过应用 Sweep 规则将小修复堆叠到您的 PR 中 Sweep 可以帮助用户快速处理小型任务,并且支持多种编程语言。