PlatformLab/NanoLog




NanoLog 是一个极其高性能的 C++ 纳秒级日志系统,提供类似 printf 的简单 API。
- 实现了每秒超过 8000 万条日志记录,在中位延迟仅略高于 7 纳秒。
- 在编译时提取静态日志信息,只在运行时热路径记录动态组件,并将格式化工作推迟到离线处理阶段,从而实现了出色的性能表现。
- 可以通过编译生成的二进制文件来输出动态日志数据,需要经过额外解压程序才能产生完整、可读的 ASCII 日志。
OpenCTI-Platform/opencti



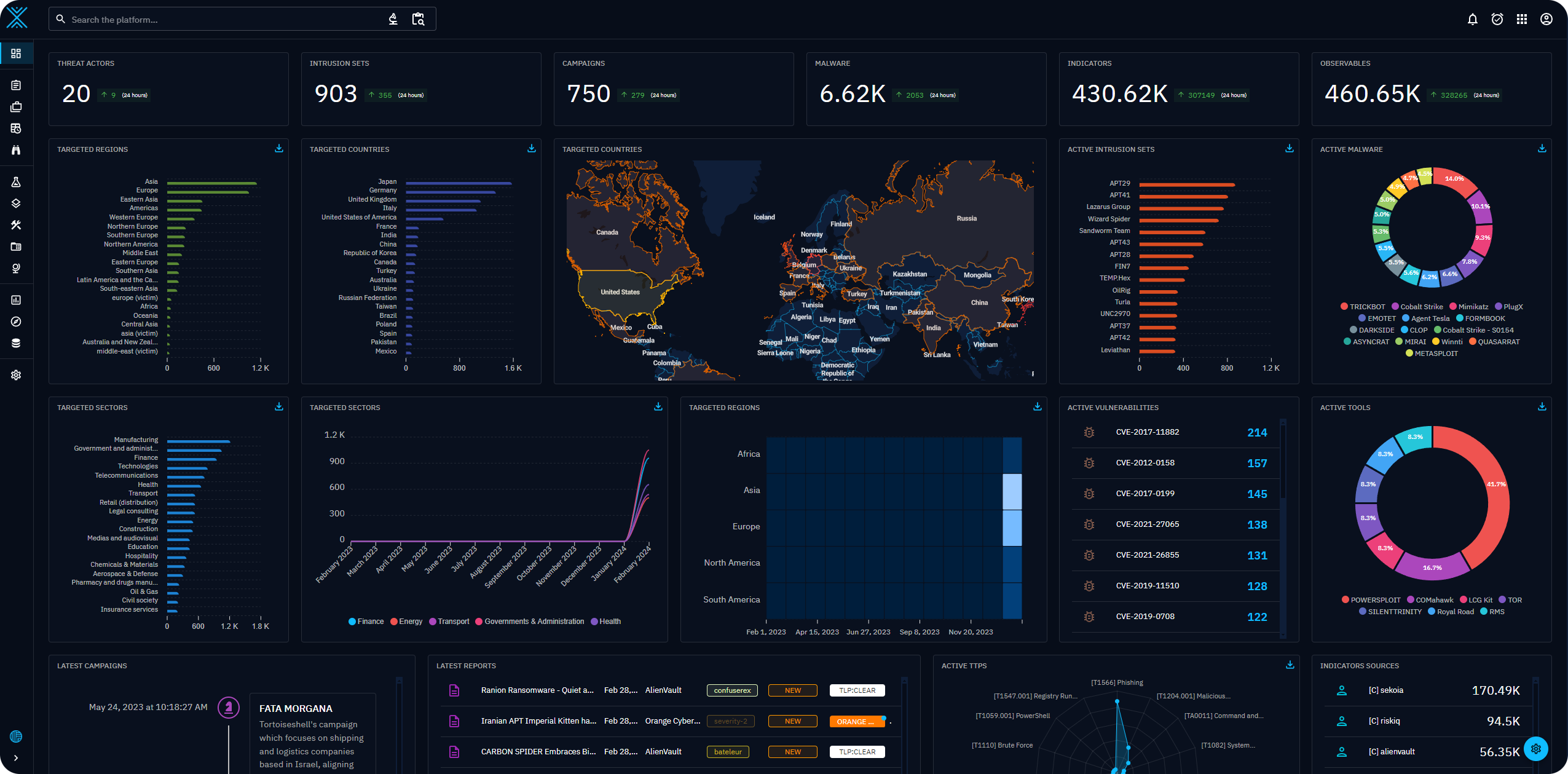
opencti 是一个开源平台,允许组织管理其网络威胁情报知识和可观察数据。
- 使用基于 STIX2 标准的知识架构对数据进行结构化。
- 包括 GraphQL API 和面向用户体验的前端。
- 可与其他工具和应用集成,如 MISP、TheHive、MITRE ATT&CK 等。
- 提供功能丰富的工具,帮助用户资本化技术信息和非技术信息,并将每个信息片段链接到其主要来源。
wistbean/learn_python3_spider



learn_python3_spider 是一个 python 爬虫教程系列项目,旨在从零开始教授学习 Python 爬虫的全过程,涵盖浏览器抓包、各种爬虫模块使用、IP 代理、验证码识别、数据库操作等内容。 该项目的主要功能和优势包括:
- 提供完整的 Python 爬虫教程系列
- 涵盖多种爬取技术和工具如 requests, beautifulSoup, selenium, scrapy 等
- 支持多线程多进程爬取以及分布式爬取
- 包含实战案例和源代码示例展示 通过这个项目,用户可以系统地学习并实践 Python 中的网络数据采集技术。
LLaVA-VL/LLaVA-NeXT




LLaVA-NeXT 是一个开源的大型多模态模型。
- 提供强大而全面的多模态功能
- 在单图像、多图像和视频任务上表现出色
- 提供详尽文档、脚本以及高质量数据集
- 支持各种架构选择并具有较低 GPU 内存需求
IdentityServer/IdentityServer4




IdentityServer4 是一个用于 ASP.NET Core 的 OpenID Connect 和 OAuth 2.0 框架。
- 提供 OpenID Connect 和 OAuth 2.0 框架
- 支持基于令牌的身份验证
- 实现单点登录功能
- 控制 API 访问权限