
hiroi-sora/Umi-OCR



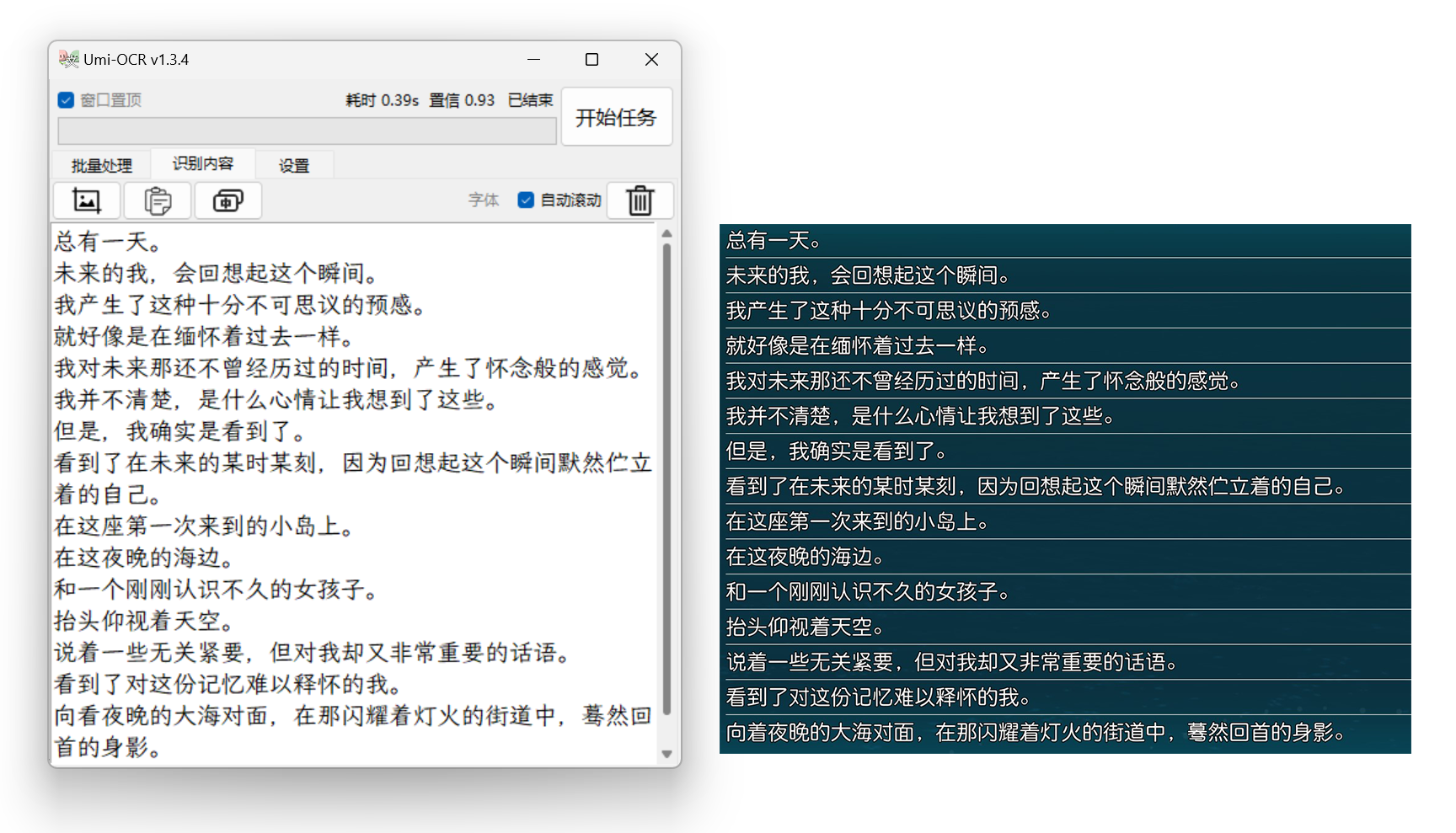
Umi-OCR 是一个免费、开源的离线 OCR 软件,适用于 Windows7 x64 及以上系统。它具有以下核心优势和功能:
- 全部代码开源,完全免费。
- 解压即可使用,无需网络连接。
- 可以批量导入处理图片,并将结果保存到本地 txt/md/jsonl 等多种格式文件中。也可以进行实时截屏识别。
- 使用高效的 PaddleOCR-json C++ 识别引擎,在电脑性能足够的情况下通常比在线 OCR 服务更快速。
- 默认采用精准度较高的 PPOCR-v3 模型库,并且对手写、方向不正、杂乱背景等情景也有良好的识别率。还支持设置忽略区域排除水印等。
apexcharts/apexcharts.js



ApexCharts 是一个现代的 JavaScript 图表库,它允许您使用简单的 API 和 100 多个预先准备好的示例构建交互式数据可视化。ApexCharts 包含超过十种图表类型,可以在应用程序和仪表板中提供美观、响应式的可视化效果。
- 支持各大主流浏览器
- 提供 npm 安装方式
- 可以直接引入 js 文件进行使用
espnet/espnet




ESPnet 是一个端到端的语音处理工具包,涵盖了端到端语音识别、文本转语音、语音翻译、语音增强、说话人分离等功能。该工具使用 pytorch 作为深度学习引擎,并遵循 Kaldi 风格的数据处理和特征提取/格式以及配方来提供各种不同的实验设置。
- 支持多个 ASR (自动演讲识别) 配方
- 支持类似于 ASR 配方一样的 TTS (文本转声)
- 支持 ST (Speech Translation) 配方
- 提供完整且易用的命令行界面和脚本接口
thuml/Time-Series-Library



TSlib 是一个开源库,用于深度学习研究,特别是深度时间序列分析。该库提供了一个整洁的代码基础来评估先进的深度时间序列模型或开发自己的模型,并涵盖五个主流任务:长期和短期预测、插补、异常检测和分类。
- 提供了一套完善的代码库
- 支持多种任务 (长期/短期预测、插补、异常检测和分类)
- 包含各类领先模型实现
termux/termux-packages



这个项目是一个包含脚本和补丁的仓库,用于构建适用于 Termux Android 应用程序的软件包。该项目提供了有关 Termux 软件包管理的快速指南,并解释了在运行 apt 或 pkg 命令时如何修复 “存储库正在维护中或已关闭” 的错误信息。
facebookresearch/llama



LLaMA 2 是一个开源项目,用于加载 LLaMA 模型并进行推理。
该项目的主要功能是提供预训练和微调后的 LLaMA 语言模型的权重和起始代码。这些模型参数范围从 7B 到 70B 不等。
以下是该项目的关键特性和核心优势:
- 支持多种规模 (7B、13B 和 70B) 的语言模型。
- 所有模型都支持最长 4096 个标记长度,并根据硬件配置预分配缓存空间。
- 预训练版本适用于文本补全任务,需要按照指定格式输入提示以获得期望答案作为自然延伸。
- 微调聊天版可以应用在对话场景中,在输入输出上遵循特定格式定义来获取所需功能与性能。