
NVIDIA/TensorRT-LLM



TensorRT-LLM 是一个用于大型语言模型的 TensorRT 工具箱,它提供了易于使用的 Python API 来定义和构建包含最先进优化的 TensorRT 引擎,用于在 NVIDIA GPU 上高效执行推理。该项目还包括创建 Python 和 C++ 运行时环境以及与 NVIDIA Triton Inference Server 集成的后端。其核心优势和主要功能如下:
- 支持从单个 GPU 到多节点多 GPU 配置
- Python API 类似于 PyTorch API,并提供常用函数 (如
einsum、softmax、matmul或者view) 和有用组件 (例如 Attention 块、MLP 或整个 Transformer 层) - 内置支持 INT4/INT8 权重量化和 SmoothQuant 技术
- 提供预定义模型并可轻松修改扩展适应自定义需求
cpacker/MemGPT



MemGPT 是一个智能地管理 LLM 中不同内存层的系统,以在有限上下文窗口内有效提供扩展上下文。它可以创建具有自编辑记忆的永久聊天机器人,并且可以与 SQL 数据库和本地文件进行对话。其核心优势包括:
- 可以将关键信息推送到向量数据库并在后续对话中检索
- 支持通过 CLI 模式作为会话代理运行
- 允许加载本地文件或者 API 文档到归档内存中进行交互查询
mit-han-lab/streaming-llm



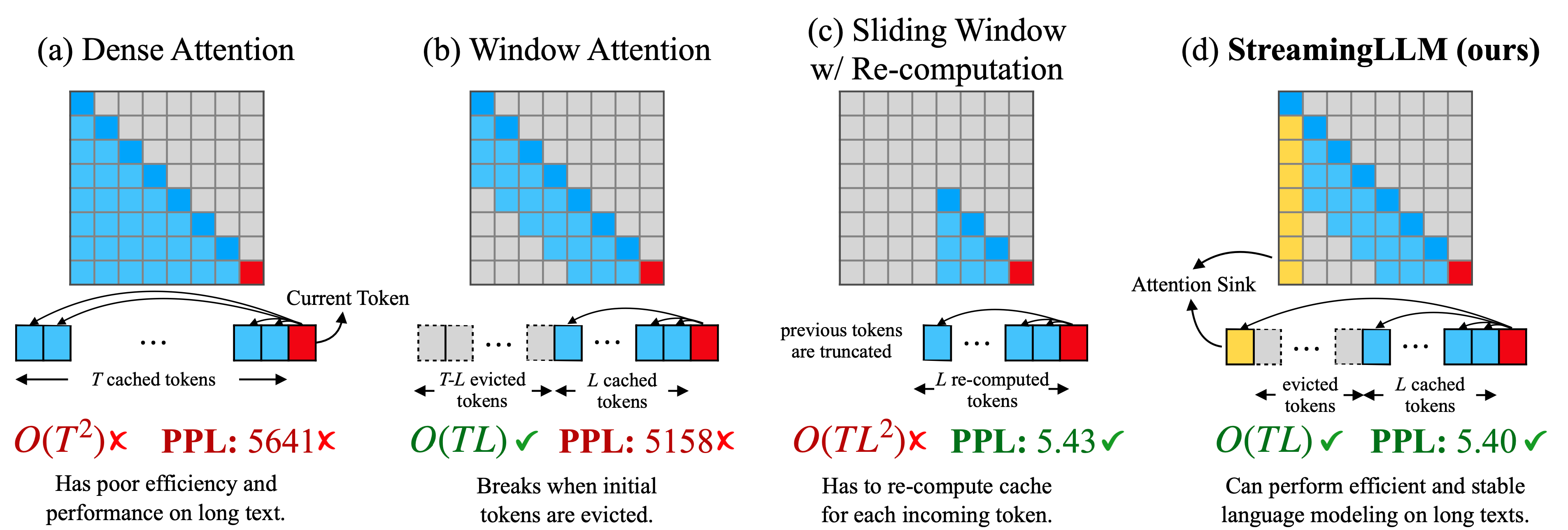
这个项目是关于使用 Attention Sinks 的高效流式语言模型。它解决了在多轮对话等流式应用中部署大规模语言模型 (LLMs) 时遇到的两个主要挑战:缓存之前标记的键和值状态 (KV) 消耗大量内存,而且常见的 LLMs 无法推广到比训练序列长度更长的文本上。该项目提出了 StreamingLLM 框架,通过保留初始令牌和注意力池来实现窗口化注意机制,并能够将有限长度注意窗口进行泛化以处理无限序列长度而不需要微调。核心优势包括:
- 可以使 Llama-2、MPT、Falcon 和 Pythia 稳定高效地执行具有 400 万以上标记数目的语言建模。
- 在流媒体设置下,相较于滑动窗口重新计算基线可以加速 22.2 倍。
songquanpeng/one-api



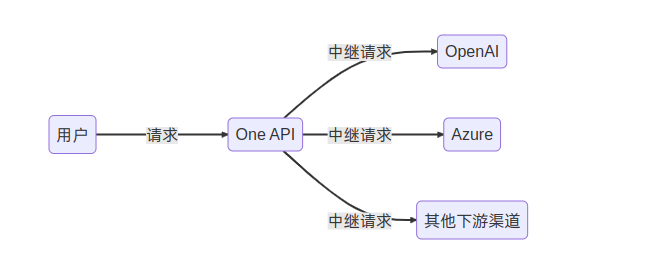
One API 是一个开源的接口管理和分发系统,旨在支持多种大型模型 (如 OpenAI ChatGPT、Anthropic Claude、Google PaLM2 等),并提供简单易用的界面。该项目具有以下关键特性和核心优势:
- 支持多种大模型:OpenAI ChatGPT 系列模型、Anthropic Claude 系列模型、Google PaLM2 系列模型等。
- 提供配置镜像以及众多第三方代理服务,包括 OpenAI-SB 和 AI Proxy。
- 可通过负载均衡方式访问不同渠道,并支持流式传输实现打字机效果。
- 支持多机部署,在令牌管理中设置过期时间和额度,并且可以进行兑换码管理批量生成与导出充值功能。
InternLM/InternLM




InternLM 是一个开源的轻量级训练框架,旨在支持模型预训练而无需大量依赖。它通过单一代码库实现了对具有数千个 GPU 的大规模集群进行预训练,并在单个 GPU 上进行微调,同时实现了显著的性能优化。InternLM 在 1024 个 GPU 上的训练过程中达到近 90% 的加速效率。
- 出色整体表现
- 强大工具调用能力
- 支持 16k 上下文长度 (通过推理外推)
- 更好地价值对齐
openai/evals



OpenAI Evals 是一个用于评估 LLMs (大型语言模型) 或使用 LLMs 作为组件构建的系统的框架。它还包括一个具有挑战性 evals 的开源注册表。Evals 现在支持通过 Completion Function Protocol 评估任何系统,包括 prompt chains 或 tool-using agents 的行为。通过 Evals,我们旨在尽可能简单地构建 eval,并编写尽量少的代码。“Eval” 是用于评估系统行为质量的任务。
- 支持运行和创建 evals
- 提供了现有 eval 模板以及如何运行已存在 eval 的指南
- 可以自定义实施特定逻辑来进行个性化 eval 逻辑