
mindsdb/mindsdb



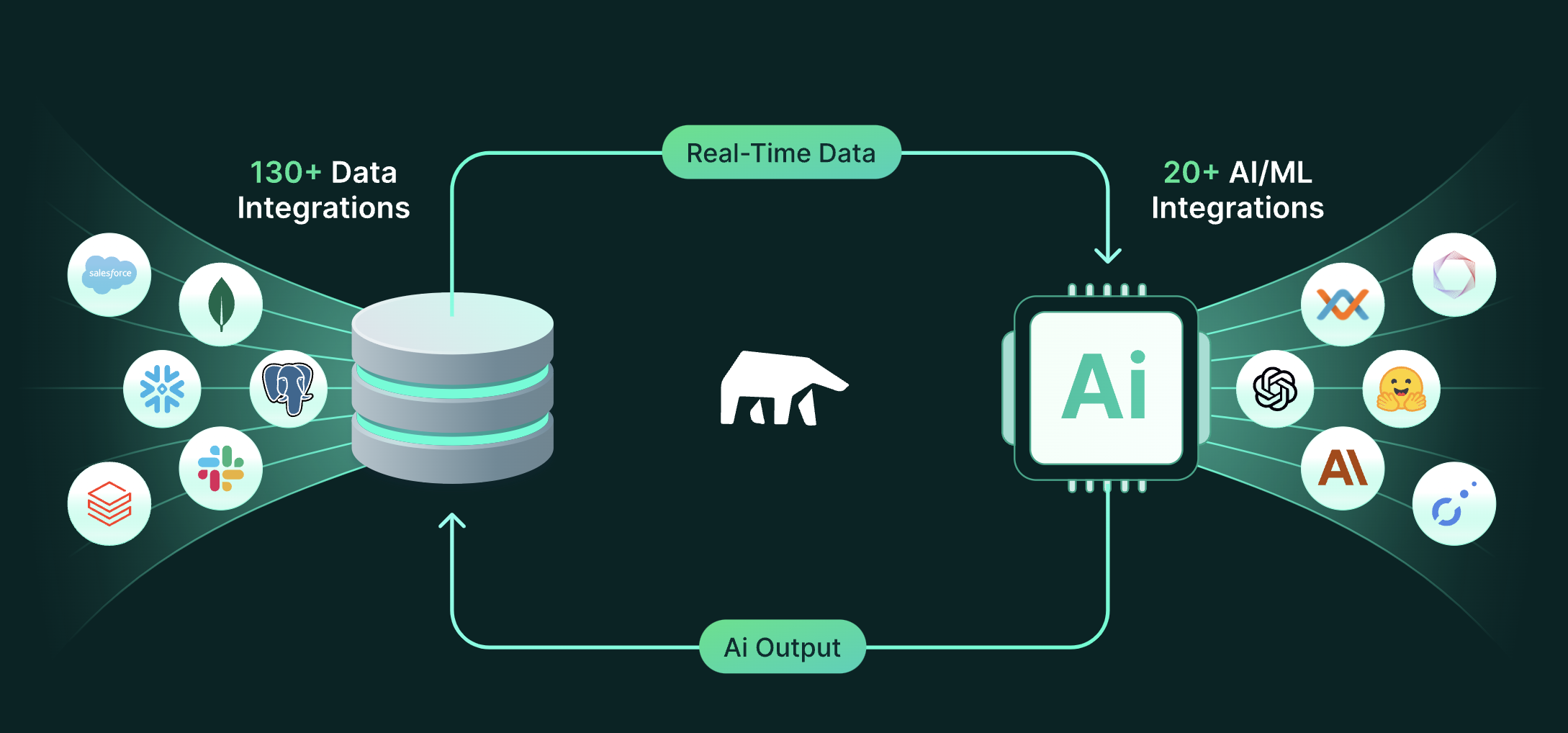
MindsDB 是一个开源项目,它的主要功能是将任何 AI/ML 模型连接到任何数据源。该项目提供以下核心优势和关键特点:
- Hook AI 模型在观察到新数据时自动运行,并将输出插入我们的任何集成中。
- 从我们支持的 130 多个数据源中包含的数据自动训练和微调 AI 模型。
- 可以使用演示环境来尝试 MindsDB 并使用最常见用例的样本数据。
- 提供了安装指南以及完整文档、社区支持等资源。
Significant-Gravitas/AutoGPT




AutoGPT 是开源 AI 代理生态系统的核心工具包。它采用模块化和可扩展的框架,使您能够专注于以下方面:
- 构建 - 为惊人之作打下基础。
- 测试 - 将您的代理调整到完美状态。
- 查看 - 观察进展成果呈现出来。
AutoGPT 始终处于 AI 创新前沿,并提供了开源生态系统中冠军代码库所需功能。 在我们目前进行基准测试的所有 Agent 中,AutoGPT 得分最高。
langchain-ai/langchain



LangChain 是一个用于通过组合性构建 LLMs 应用程序的库。
- LLMs 和 Prompts:包括 prompt 管理、prompt 优化、所有 LLM 的通用接口以及与 LLMs 一起使用的常见工具。
- Chains:超越单个 LLM 调用,涉及到多次调用 (无论是对 LLM 还是其他实用工具)。LangChain 为链提供了标准接口、许多与其他工具集成的功能,并提供了常见应用程序的端到端链示例。
- 数据增强生成:数据增强生成涉及特定类型的链首先与外部数据源进行交互,获取在生成步骤中使用的数据。例如长文本摘要和针对特定数据源进行问答等。
- Agents:代理机制使得 LLMS 可以决策采取哪些行动,执行该操作并观察结果,然后重复此过程直至完成。LangChain 提供了代理机制的标准界面,多种可选代理模型和完整示例。
- Memory:内存指持久保存 chain/agent 调度之间状态信息。Langchain 提供内存方案标准接口,同时也有大量相关代码示例
- Evaluation:[BETA] 使用传统评估方法很难评估产生式模型。一种新颖方式是利用语言模型自身来做这项评估。LangChain 提供了一些辅助这种方式的 prompt/chain
guidance-ai/guidance



Guidance 是一个强大的工具,可以让您更有效地掌控现代语言模型,无论您是开发者、设计师还是跨职能团队。它允许您以一种简单直观的语法,基于 Handlebars 模板,实现文本生成、提示和逻辑控制的混合,产生清晰和易于理解的输出结构。它支持Jupyter/VSCode笔记本中的实时流式处理,可用于快速开发和测试复杂的模板和生成。此外,Guidance 还提供了模型加速功能,可在处理多个生成或 LLM(大型语言模型)控制流语句时显着提高推理性能,从而提供更快的结果。 Guidance 具有以下主要特点:
- 简单、直观的语法,基于 Handlebars 模板。
- 丰富的输出结构,包括多个生成、选择、条件、工具使用等。
- 在 Jupyter/VSCode 笔记本中的实时流式处理,提高了模板开发效率。
- 智能的基于种子的生成缓存,优化了生成速度。
- 支持基于角色的聊天模型(如 ChatGPT )的轻松集成。
- 与 Hugging Face 模型的轻松集成,包括提供模型加速、边界优化和正则表达式模式引导等功能。
- Guidance 的目标是使文本生成和模型控制更加灵活、高效,为开发者和团队提供更多自由度和便利性。它适用于多种用途,包括自然语言生成、文本处理和实时流式处理。
无论您是初学者还是经验丰富的开发者,Guidance都能为您的项目带来便利和效率,是一个值得尝试的开源工具。
openai/evals



OpenAI Evals 是一个用于评估 LLMs (大型语言模型) 或使用 LLMs 作为组件构建的系统的框架。它还包括一个具有挑战性 evals 的开源注册表。Evals 现在支持通过 Completion Function Protocol 评估任何系统,包括 prompt chains 或 tool-using agents 的行为。通过 Evals,我们旨在尽可能简单地构建 eval,并编写尽量少的代码。“Eval” 是用于评估系统行为质量的任务。
- 支持运行和创建 evals
- 提供了现有 eval 模板以及如何运行已存在 eval 的指南
- 可以自定义实施特定逻辑来进行个性化 eval 逻辑
karpathy/nanoGPT




nanoGPT 是一个用于训练/微调中型 GPT 的最简单、最快速的存储库。它是 minGPT 的重写,注重实践而非教育。该项目仍在积极开发中,但目前文件 train.py 可以在 OpenWebText 上复现运行时间约为4天,在一台 8XA100 40GB 节点上进行训练,并且能够复制出 GPT-2 (124M) 模型。代码本身很简洁易懂:train.py 只有大约 300 行样板化训练循环代码和 model.py 只有大约 300 行 GPT 模型定义,可选择从 OpenAI 加载 GTP-2 的权重。这就是全部。
- 训练/微调中等规模的语言生成模型
- 简单易读:由于代码十分简洁,因此非常容易根据个人需求进行修改。
- 快速高效:在适当硬件资源下,能够在较短时间内完成对不同数据集大小及网络结构参数设置下的语言生成任务。