
apple/ml-ferret



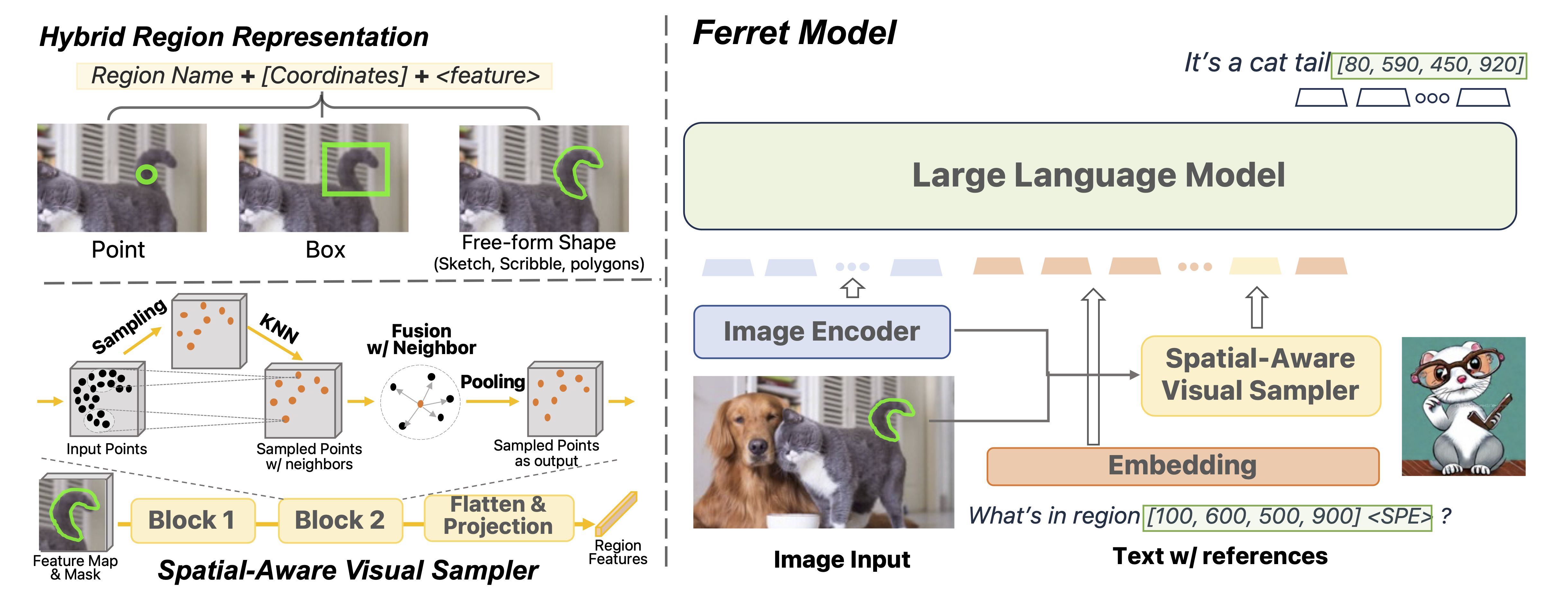
Ferret 是一个端到端的 MLLM (多模态语言和视觉学习) 模型,可以接受任何形式的指代,并在响应中对任何内容进行定位。其主要功能包括 FERRET 模型、GRIT 数据集以及 Ferret-Bench 评估基准。该项目的关键优势和核心特点包括:
- FERRET 模型采用混合区域表示+空间感知视觉采样器,实现了细粒度且开放词汇表范围内的指称与定位。
- GRIT 数据集规模大、层次化且稳健,在调整指令方面具有重要意义。
- Ferret-Bench 是一个多模态评估基准,同时需要涵盖指称/定位、语义理解、知识获取和推理等能力。
ise-uiuc/magicoder



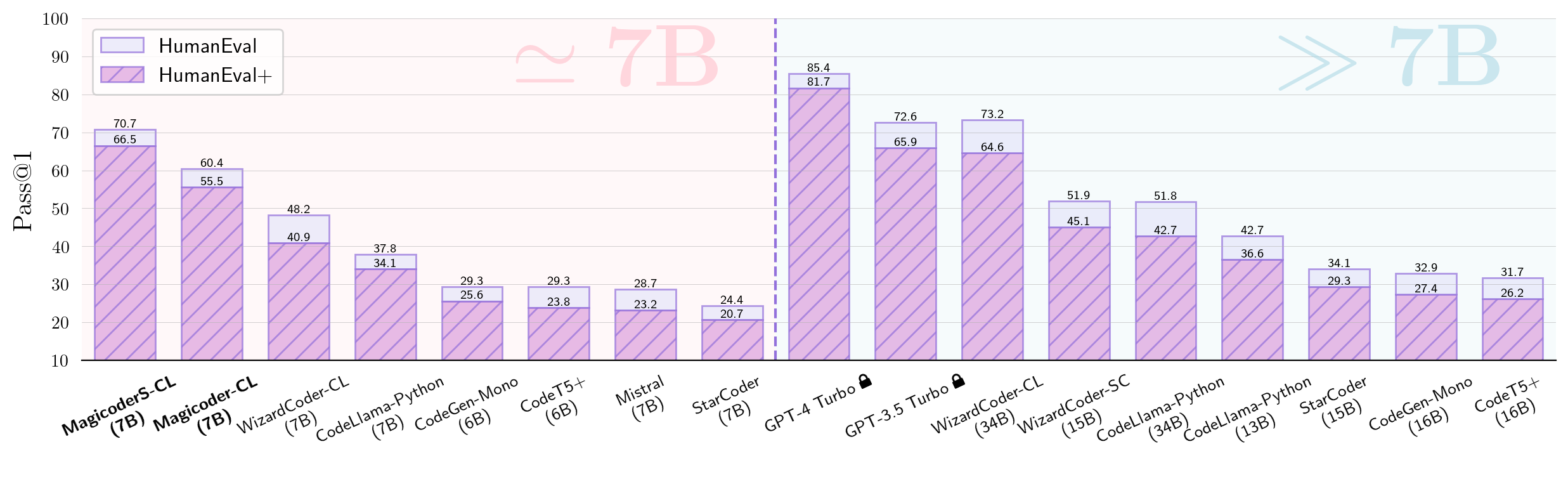
Magicoder 是一个由 🪄OSS-Instruct 提供支持的模型系列,它采用一种新颖的方法来启发 LLMs 使用开源代码片段生成低偏差和高质量指令数据。🪄OSS-Instruct 通过赋予 LLM 丰富的开源参考资料,以产生更多样化、真实和可控制的数据,从而减轻了 LLM 合成指令数据固有的偏见。
01-ai/Yi



Yi 系列模型是由 01.AI 的开发人员从头开始训练的大型语言模型。第一个公开发布版本包含两个双语 (英文/中文) 基础模型,参数大小分别为 6B 和 34B。它们都使用 4K 序列长度进行训练,并在推理时可以扩展到 32K。
- 支持多种任务评估
- 提供了不同规模和上下文长度的预训练模型
- 可以通过 Docker 或本地环境来使用该项目
THUDM/ChatGLM3



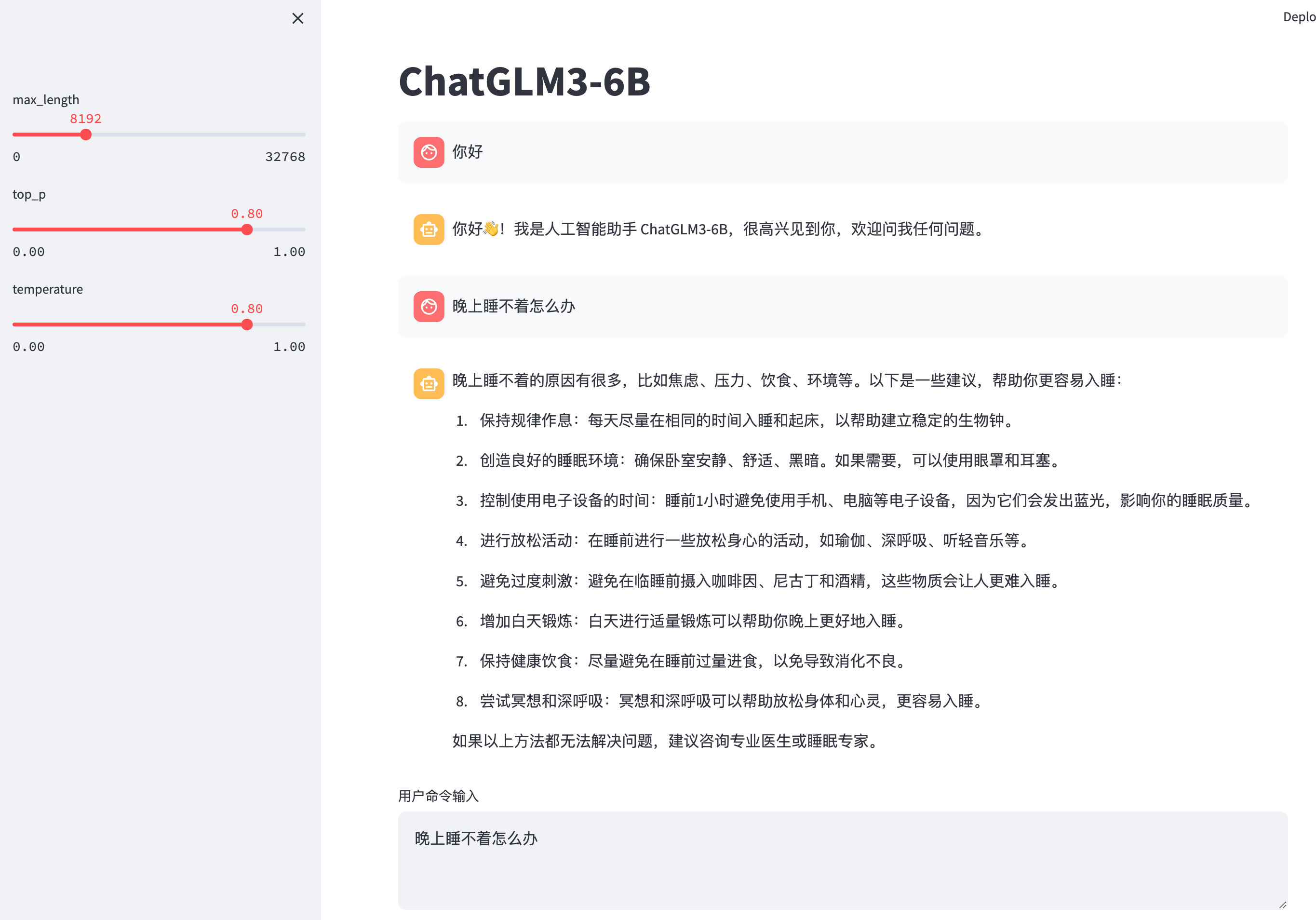
ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的新一代对话预训练模型。其主要功能包括更强大的基础模型、更完整的功能支持以及全面开源序列。具体特点如下:
- 更强大的基础模型:ChatGLM3-6B 采用了更多样化、充分训练步数和合理训练策略,在不同角度数据集上表现出最佳性能。
- 更完整的功能支持:引入全新设计 Prompt 格式,并原生支持工具调用、代码执行和 Agent 任务等复杂场景。
- 全面开源序列:除了对话模型外,还提供了基础模型 ChatGLM3-6B-base 和长文本对话模型 ChatGLM3-6B32K。
QwenLM/Qwen



Qwen 是一个开源项目,主要功能是提供强大的基础语言模型和聊天模型。它们经过稳定预训练,并使用多达 3 万亿个标记的跨领域、多语种数据进行了广泛覆盖。这些模型能够在基准数据集上取得竞争性表现。Qwen-Chat 还具有与人类偏好相一致的对话能力,可以用于聊天、内容创作、信息提取等任务,并且可以使用工具、扮演代理角色甚至充当代码解释器等功能。 以下是该项目的关键特点和核心优势:
- 提供强大而稳定的基础语言模型
- 聊天模型与人类偏好保持一致
- 可以执行各种任务,如聊天、创建内容、信息提取等
- 支持工具使用和代理角色操作