
alibaba-damo-academy/FunASR



FunASR 是一个基础的语音识别工具包,提供了多种功能,包括语音识别(ASR)、语音活动检测(VAD)、标点还原、语言模型、说话人验证、说话人分离和多讲者 ASR。该项目发布了大量学术和工业预训练模型,并通过 Model Zoo 和 huggingface 进行开源。其中代表性的 Paraformer-large 模型具有高准确性、高效率和便捷部署等优势,支持快速构建语音识别服务。同时提供方便的脚本和教程以及对预训练模型进行推理和微调的支持。
m-bain/whisperX



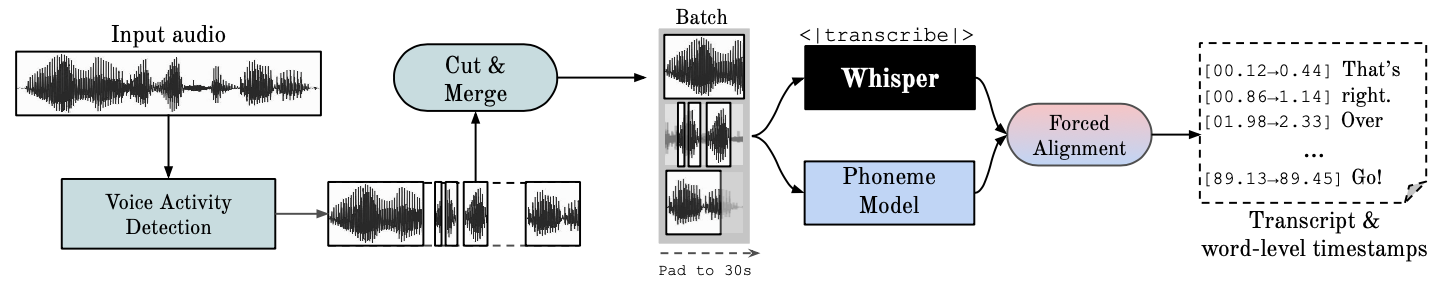
WhisperX 是一个开源项目,具有单词级时间戳和说话人分离功能。
- 使用 whisper large-v2 进行批量推理,以达到 70 倍的实时转录
- faster-whisper 后端更快,并且对于 large-v2 模型只需要小于 8GB GPU 内存
- 使用 wav2vec2 对齐来获得准确的单词级时间戳
- 利用 pyannote-audio 中的说话人分离技术进行多说话人 ASR (带有说话者 ID 标签)
- VAD 预处理可以降低幻听问题,并在不影响 WER 情况下进行批处理
ggerganov/whisper.cpp



whisper.cpp 是一个高性能的 OpenAI Whisper 自动语音识别 (ASR) 模型推理项目。它具有以下主要功能和核心优势:
- 无依赖的纯 C/C++实现
- 针对 Apple Silicon 进行了 ARM NEON、Accelerate 框架和 Core ML 的优化,成为首选平台
- 支持 x86 体系结构上的 AVX 指令集以及 POWER 体系结构上的 VSX 指令集
- 混合 F16/F32 精度支持
- 支持 4 位和 5 位整数量化
- 低内存使用 (Flash Attention)
- 运行在 CPU 上,并部分支持 NVIDIA GPU;通过 cuBLAS 以及部分支持 OpenCL GPU; 通过 CLBlast 加速计算。
该项目还提供了丰富而全面的平台支持,包括 Mac OS、iOS、Android、Java 等多个操作系统/环境。
此外,whisper.cpp 还具有以下特点:
- 轻量级模型实现:将整个模型实现压缩到 2 个源文件中,方便在不同平台和应用程序中轻松集成。
- 提供示例代码:演示如何使用库进行样本音频转录以及从麦克风获取实时音频并进行转录。
- 各种绑定可用:提供各种编程语言 (如 Rust、Javascript、Go 等) 下与 Whisper 交互的绑定。
- 提供多个示例项目:包括命令行工具、语音助手应用程序以及在浏览器中运行 Whisper 等。
Const-me/Whisper



这个项目是 OpenAI Whisper 自动语音识别 (ASR) 模型的 C++ 移植版本。该项目在 Windows 平台上实现了 Whisper.cpp,并提供了一些核心优势和主要功能:
- 基于 DirectCompute 的跨厂商通用 GPGPU 技术
- 纯 C++ 实现,除操作系统组件外无运行时依赖
- 比 OpenAI 原始实现更快速
- 支持混合 F16/F32 精度计算
- 内置性能分析器来测量各个计算着色器执行时间
- 低内存使用率 此外还有其他特点包括支持多种音频格式、媒体处理基础设施以及易于使用 COM 风格 API 等。
AIGC-Audio/AudioGPT



AudioGPT 是一个理解和生成语音、音乐、声音和虚拟人的开源项目。
主要功能:
- 文本转语音
- 风格迁移
- 语音识别
- 语言增强 (Speech Enhancement)
- 声学分离 (Speech Separation)
该项目具有以下核心优势:
- 多领域支持:AudioGPT 在多个领域都提供了强大的支持,包括文本到语言合成、风格迁移以及各种与声学相关任务。无论您需要什么样的应用场景,在这个项目中都能找到满足需求的模型。
- 先进技术实现:AudioGPT 采用最先进的基础模型来实现其功能,如 FastSpeech,SyntaSpeech 等。这些高质量模型经过训练完善调试后发布给用户使用。