
myshell-ai/MeloTTS




MeloTTS 是 MyShell.ai 开发的高质量多语言文本转语音库。
- 支持英语、西班牙语、法语、中文、日本和韩国等多种语言。
- 中文发音支持混合中英文。
- 足够快速以进行 CPU 实时推断。
collabora/WhisperSpeech



WhisperSpeech 是一个通过反向 Whisper 构建的开源文本到语音系统。 该项目的主要功能、关键特性和核心优势包括:
- 以开源模型为基础,如 Whisper from OpenAI、EnCodec from Meta 和 Vocos from Charactr Inc。
- 训练模型使用合法授权的语音录音,并且所有代码都是开源的,因此在商业应用中始终安全可靠。
- 目前模型基于英文 LibreLight 数据集训练,下一版本计划支持多种语言。
RVC-Boss/GPT-SoVITS



GPT-SoVITS 是一个强大的少样本语音转换和文本到语音 WebUI。 该项目主要功能、关键特性、核心优势包括:
- 零样本 TTS:输入 5 秒的声音样本,即可进行文本到语音转换。
- 少样本 TTS:只需 1 分钟的训练数据即可微调模型,提高语音相似度和真实感。
- 跨语言支持:支持英文、日文和中文等不同于训练数据集的推理。
- WebUI 工具:集成了声伴分离、自动训练集分割、中文 ASR 和文字标注等工具,帮助初学者创建训练数据集和 GPT/SoVITS 模型。
yl4579/StyleTTS2



这个项目是 StyleTTS 2,它是一个文本到语音 (TTS) 模型,通过使用大规模语音语言模型的风格扩散和对抗训练来实现人类级别的 TTS 合成。其主要功能包括利用扩散模型将风格建模为潜在随机变量以生成最适合文本的样式,并采用大规模预训练 SLM 作为鉴别器进行端到端培训。该项目具有以下关键特点和核心优势:
- 利用扩散技术有效地产生多样化的语音合成
- 使用大规模预训练 SLMs 提高了语音自然度
- 在单发声者 LJSpeech 数据集上超越了人类录制,在多发声者 VCTK 数据集上与之匹配
- 对 LibriTTS 数据集进行培训时,能够胜过先前公开可获得的零冲击说话者适应性
jaywalnut310/vits



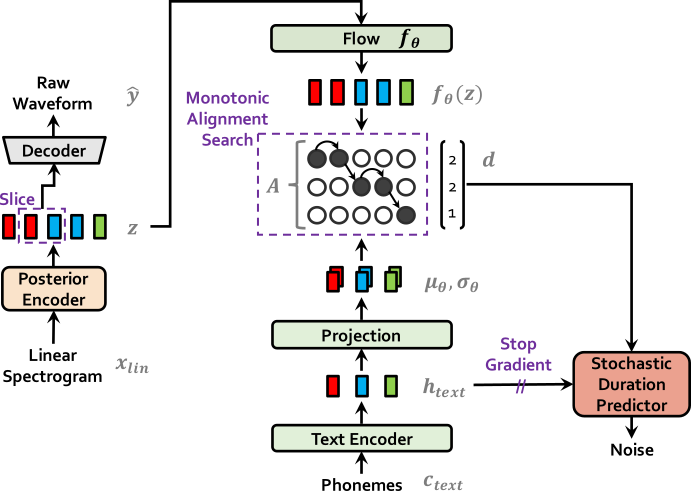
vits 是一个用于端到端文本转语音的条件变分自动编码器和对抗学习的项目。 该项目提出了一种并行端到端 TTS 方法,采用了变分推断、正则化流和对抗训练过程,以改善生成建模的表现力。此外,还提出了一种随机持续时间预测器,可以从输入文本中合成具有不同节奏的语音。通过概率建模来表达自然多样性关系,并在主观人类评估中显示出优异性能。
- 采用条件变分自动编码器
- 使用对抗学习
- 支持单阶段训练和并行采样
- 提供预训练模型